
Explorative Datenanalyse - Exploratory data analysis
| Teil einer Serie über Statistik |
| Datenvisualisierung |
|---|
| Hauptabmessungen |
| Wichtige Zahlen |
| Informationsgrafiktypen |
| verwandte Themen |
In der Statistik ist die explorative Datenanalyse ein Ansatz zur Analyse von Datensätzen, um ihre Hauptmerkmale zusammenzufassen, wobei häufig statistische Grafiken und andere Datenvisualisierungsmethoden verwendet werden. Ein statistisches Modell kann verwendet werden oder nicht, aber in erster Linie dient EDA dazu, zu sehen, was uns die Daten über die formale Modellierungs- oder Hypothesentestaufgabe hinaus sagen können. Die explorative Datenanalyse wird seit 1970 von John Tukey gefördert, um Statistiker zu ermutigen, die Daten zu untersuchen und möglicherweise Hypothesen zu formulieren, die zu neuen Datensammlungen und Experimenten führen könnten. EDA unterscheidet sich von der anfänglichen Datenanalyse (IDA) , die sich enger auf die Überprüfung von Annahmen konzentriert, die für die Modellanpassung und das Testen von Hypothesen erforderlich sind, sowie den Umgang mit fehlenden Werten und die erforderlichen Transformationen von Variablen. EDA umfasst IDA.
Überblick
Tukey definierte die Datenanalyse 1961 als: "Verfahren zur Analyse von Daten, Techniken zur Interpretation der Ergebnisse solcher Verfahren, Möglichkeiten zur Planung der Datensammlung, um ihre Analyse einfacher, genauer oder genauer zu machen, und alle Maschinen und Ergebnisse von ( mathematische) Statistiken, die sich auf die Analyse von Daten beziehen."
Tukeys Befürwortung der EDA förderte die Entwicklung von Paketen für statistische Berechnungen , insbesondere von S bei Bell Labs . Die Programmiersprache S inspirierte die Systeme S-PLUS und R . Diese Familie von statistischen Computerumgebungen zeichnete sich durch stark verbesserte dynamische Visualisierungsfunktionen aus, die es Statistikern ermöglichten, Ausreißer , Trends und Muster in Daten zu identifizieren , die einer weiteren Untersuchung bedürfen.
Tukeys EDA stand in Zusammenhang mit zwei anderen Entwicklungen in der statistischen Theorie : robuste Statistik und nichtparametrische Statistik , die beide versuchten, die Empfindlichkeit statistischer Schlussfolgerungen gegenüber Fehlern bei der Formulierung statistischer Modelle zu verringern . Tukey förderte die Verwendung einer fünfstelligen Zusammenfassung numerischer Daten – den beiden Extremen ( Maximum und Minimum ), dem Median und den Quartilen –, da dieser Median und die Quartile als Funktionen der empirischen Verteilung für alle Verteilungen definiert sind, im Gegensatz zum Mittelwert und Standardabweichung ; Darüber hinaus sind die Quartile und der Median robuster gegenüber schiefen oder stark taillierten Verteilungen als herkömmliche Zusammenfassungen (Mittelwert und Standardabweichung). Die Pakete S , S-PLUS und R enthalten Routinen Resampling Statistiken , wie Quenouille und Tukey- Klappmesser und Efron ‚s Bootstrap , das sind nichtparametrischer und robust (für viele Probleme).
Explorative Datenanalyse, robuste Statistik, nichtparametrische Statistik und die Entwicklung statistischer Programmiersprachen erleichterten die Arbeit der Statistiker an wissenschaftlichen und technischen Problemen. Zu diesen Problemen gehörten die Herstellung von Halbleitern und das Verständnis von Kommunikationsnetzen, die Bell Labs betrafen. Diese statistischen Entwicklungen, die alle von Tukey verfochten wurden, wurden entwickelt, um die analytische Theorie des Testens statistischer Hypothesen zu ergänzen , insbesondere die Betonung der Laplace- Tradition auf exponentielle Familien .
Entwicklung

John W. Tukey schrieb das Buch Exploratory Data Analysis 1977 Tukey , dass zu viel Gewicht in der Statistik statt auf platziert Statistischer Test (bestätigende Datenanalyse); Es müsse mehr Gewicht auf die Verwendung von Daten gelegt werden , um Hypothesen zum Testen vorzuschlagen. Insbesondere vertrat er die Auffassung, dass eine Verwechslung der beiden Analysearten und deren Anwendung auf denselben Datensatz aufgrund der Probleme, die dem Testen der von den Daten vorgeschlagenen Hypothesen innewohnen, zu systematischen Verzerrungen führen kann .
Die Ziele der EDA sind:
- Hypothesen über die Ursachen beobachteter Phänomene vorschlagen
- Annahmen beurteilen, auf denen statistische Inferenzen basieren
- Unterstützung bei der Auswahl geeigneter statistischer Werkzeuge und Techniken
- Schaffen Sie eine Grundlage für die weitere Datenerhebung durch Umfragen oder Experimente
Viele EDA-Techniken wurden in das Data Mining übernommen . Sie werden auch jungen Studenten beigebracht, um sie an das statistische Denken heranzuführen.
Techniken und Werkzeuge
Es gibt eine Reihe von Werkzeugen, die für EDA nützlich sind, aber EDA zeichnet sich eher durch die eingenommene Einstellung als durch bestimmte Techniken aus.
Typische grafische Techniken, die in EDA verwendet werden, sind:
- Box-Plot
- Histogramm
- Multi-Vari-Diagramm
- Laufdiagramm
- Pareto-Diagramm
- Streudiagramm
- Stamm-Blatt-Plot
- Parallelkoordinaten
- Wahrscheinlichkeit
- Gezielte Projektionsverfolgung
- Glyphenbasierte Visualisierungsmethoden wie PhenoPlot und Chernoff Faces
- Projektionsmethoden wie Grand Tour, Guided Tour und Manual Tour
- Interaktive Versionen dieser Plots
- Mehrdimensionale Skalierung
- Hauptkomponentenanalyse (PCA)
- Multilineare PCA
- Nichtlineare Dimensionsreduktion (NLDR)
- Ikonographie von Zusammenhängen
Typische quantitative Techniken sind:
Geschichte
Viele EDA-Ideen lassen sich auf frühere Autoren zurückführen, zum Beispiel:
- Francis Galton betonte Ordnungsstatistiken und Quantile .
- Arthur Lyon Bowley verwendete Vorläufer des Stemplots und der Fünf-Zahlen-Zusammenfassung (Bowley verwendete tatsächlich eine „ siebenstellige Zusammenfassung “, einschließlich der Extreme, Dezile und Quartile , zusammen mit dem Median – siehe sein Elementary Manual of Statistics (3. Aufl., 1920 .). ), S. 62– er definiert „das Maximum und Minimum, Median, Quartile und zwei Dezile“ als die „sieben Positionen“).
- Andrew Ehrenberg formulierte eine Philosophie der Datenreduktion (siehe sein gleichnamiges Buch).
Der Open University- Kurs Statistik in der Gesellschaft (MDST 242) hat die obigen Ideen aufgegriffen und mit Gottfried Noethers Arbeit verschmolzen , die statistische Inferenz über Münzwurf und den Mediantest einführte .
Beispiel
Die Ergebnisse der EDA sind orthogonal zur primären Analyseaufgabe. Betrachten Sie zur Veranschaulichung ein Beispiel von Cook et al. wobei die Analyseaufgabe darin besteht, die Variablen zu finden, die das Trinkgeld, das eine Speisegesellschaft dem Kellner gibt, am besten vorhersagen. Die in den für diese Aufgabe erhobenen Daten verfügbaren Variablen sind: Trinkgeldbetrag, Gesamtrechnung, Geschlecht des Zahlers, Raucher-/Nichtraucherbereich, Tageszeit, Wochentag und Größe der Party. Die primäre Analyseaufgabe wird durch Anpassen eines Regressionsmodells angegangen, bei dem die Tipprate die Antwortvariable ist. Das angepasste Modell ist
- ( Spitzenrate ) = 0,18 - 0,01 × (Gruppengröße)
das besagt, dass die Trinkgeldrate um 1% sinkt, wenn die Größe der Essensgruppe um eine Person steigt (was zu einer höheren Rechnung führt).
Die Untersuchung der Daten zeigt jedoch andere interessante Merkmale, die von diesem Modell nicht beschrieben werden.
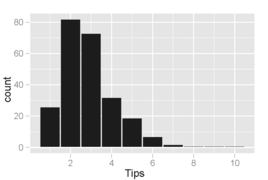
Histogramm der Trinkgeldbeträge, bei denen die Behälter 1-Dollar-Schritte abdecken. Die Verteilung der Werte ist rechtsschief und unimodal, wie es bei Verteilungen kleiner, nicht negativer Mengen üblich ist.

Histogramm der Trinkgeldbeträge, bei denen die Behälter Inkremente von 0,10 USD abdecken. Ein interessantes Phänomen ist sichtbar: Spitzen treten bei ganzen und halben Dollarbeträgen auf, die dadurch verursacht werden, dass Kunden runde Zahlen als Trinkgelder auswählen. Dieses Verhalten ist auch bei anderen Arten von Einkäufen üblich, beispielsweise bei Benzin.

Streudiagramm von Trinkgeldern vs. Rechnung. Punkte unterhalb der Linie entsprechen Trinkgeldern, die niedriger sind als erwartet (für diesen Rechnungsbetrag), und Punkte oberhalb der Linie sind höher als erwartet. Wir erwarten möglicherweise eine enge, positive lineare Assoziation, aber stattdessen eine Variation, die mit der Trinkgeldmenge zunimmt . Insbesondere unten rechts gibt es mehr Punkte weit weg von der Linie als oben links, was darauf hindeutet, dass mehr Kunden sehr günstig als sehr großzügig sind.

Streudiagramm der Trinkgelder vs. Rechnung getrennt nach Geschlecht des Zahlers und Status der Raucherabteilung. Rauchergruppen haben viel mehr Variabilität in den Trinkgeldern, die sie geben. Männer neigen dazu, die (wenigen) höheren Rechnungen zu bezahlen, und die Nichtraucherinnen neigen dazu, sehr konstant Trinkgelder zu geben (mit drei auffälligen Ausnahmen in der Stichprobe).




Was aus den Diagrammen gelernt wird, unterscheidet sich von dem, was durch das Regressionsmodell veranschaulicht wird, obwohl das Experiment nicht darauf ausgelegt war, einen dieser anderen Trends zu untersuchen. Die bei der Untersuchung der Daten gefundenen Muster legen Hypothesen über das Trinkgeld nahe, die möglicherweise nicht im Voraus vorhergesehen wurden und die zu interessanten Folgeexperimenten führen könnten, bei denen die Hypothesen formal formuliert und durch das Sammeln neuer Daten getestet werden.
Software
- JMP , ein EDA-Paket des SAS Institute .
- KNIME , Konstanz Information Miner – Open-Source-Datenexplorationsplattform auf Basis von Eclipse.
- Minitab , ein EDA- und allgemeines Statistikpaket, das in Industrie- und Unternehmensumgebungen weit verbreitet ist.
- Orange , eine Open-Source- Software-Suite für Data Mining und Machine Learning .
- Python , eine Open-Source-Programmiersprache, die in Data Mining und maschinellem Lernen weit verbreitet ist.
- R , eine Open-Source-Programmiersprache für statistische Berechnungen und Grafiken. Zusammen mit Python eine der beliebtesten Sprachen für Data Science.
- TinkerPlots ist eine EDA-Software für Schüler der oberen Grund- und Mittelstufe.
- Weka ist ein Open-Source-Data-Mining-Paket, das Visualisierungs- und EDA-Tools wie gezielte Projektionsverfolgung enthält .
Siehe auch
- Anscombes Quartett über die Bedeutung der Erforschung
- Datenbaggerung
- Prädiktive Analysen
- Strukturierte Datenanalyse (Statistik)
- Konfigurierbare Frequenzanalyse
- Beschreibende Statistik
Verweise
Literaturverzeichnis
- Andrienko, N & Andrienko, G (2005) Explorative Analyse von räumlichen und zeitlichen Daten. Ein systematischer Ansatz . Springer. ISBN 3-540-25994-5
- Cook, D. und Swayne, DF (mit A. Buja, D. Temple Lang, H. Hofmann, H. Wickham, M. Lawrence) (2007-12-12). Interaktive und dynamische Grafiken zur Datenanalyse: Mit R und GGobi . Springer. ISBN 9780387717616.CS1-Wartung: mehrere Namen: Autorenliste ( Link )
- Hoaglin, DC; Mosteller, F & Tukey, John Wilder (Hrsg.) (1985). Erkunden von Datentabellen, Trends und Formen . ISBN 978-0-471-09776-1.CS1-Pflege: mehrere Namen: Autorenliste ( Link ) CS1-Pflege: Zusatztext: Autorenliste ( Link )
- Hoaglin, DC; Mosteller, F & Tukey, John Wilder (Hrsg.) (1983). Robuste und explorative Datenanalyse verstehen . ISBN 978-0-471-09777-8.CS1-Pflege: mehrere Namen: Autorenliste ( Link ) CS1-Pflege: Zusatztext: Autorenliste ( Link )
- Inselberg, Alfred (2009). Parallele Koordinaten: Visuelle mehrdimensionale Geometrie und ihre Anwendungen . London New York: Springer. ISBN 978-0-387-68628-8.
- Leinhardt, G., Leinhardt, S., Exploratory Data Analysis: New Tools for the Analysis of Empirical Data , Review of Research in Education, Vol. 2 , No. 8, 1980 (1980), S. 85–157.
- Martinez, WL ; Martinez, AR & Solka, J. (2010). Explorative Datenanalyse mit MATLAB, zweite Auflage . Chapman & Hall/CRC. ISBN 9781439812204.
- Theus, M., Urbanek, S. (2008), Interaktive Grafiken zur Datenanalyse: Prinzipien und Beispiele, CRC Press, Boca Raton, FL, ISBN 978-1-58488-594-8
- Tucker, L; MacCallum, R. (1993). Explorative Faktorenanalyse . [1] .
- Tukey, John Wilder (1977). Explorative Datenanalyse . Addison-Wesley. ISBN 978-0-201-07616-5.
- Velleman, PF; Hoaglin, DC (1981). Anwendungen, Grundlagen und Computing der explorativen Datenanalyse . ISBN 978-0-87150-409-8.
- Young, FW Valero-Mora, P. und Friendly M. (2006) Visuelle Statistik: Anzeigen Ihrer Daten mit dynamischen interaktiven Grafiken . Wiley ISBN 978-0-471-68160-1
- Jambu M. (1991) Explorative und multivariate Datenanalyse . Akademische Presse ISBN 0123800900
- SHC DuToit, AGW Steyn, RH Stumpf (1986) Grafische Explorative Datenanalyse . Springer ISBN 978-1-4612-9371-2