
Gradientenabstieg - Gradient descent
Gradientenabfallsaktualisierung ist eine erste Ordnung iterative Optimierung Algorithmus ein für die Suche nach lokalen Minimum einer differenzierbare Funktion . Die Idee ist, wiederholte Schritte in die entgegengesetzte Richtung des Gradienten (oder ungefähren Gradienten) der Funktion am aktuellen Punkt zu machen, da dies die Richtung des steilsten Abstiegs ist. Umgekehrt führt ein Schritt in Richtung des Gradienten zu einem lokalen Maximum dieser Funktion; der Vorgang wird dann als Gefälleaufstieg bezeichnet .
Der Gradientenabstieg wird im Allgemeinen Cauchy zugeschrieben , der sie erstmals 1847 vorschlug. Hadamard schlug 1907 unabhängig eine ähnliche Methode vor. Seine Konvergenzeigenschaften für nichtlineare Optimierungsprobleme wurden erstmals 1944 von Haskell Curry untersucht , wobei die Methode immer besser untersucht wurde und in den folgenden Jahrzehnten verwendet, oft auch als steilste Abfahrt bezeichnet.
Beschreibung

Gradientenabstieg liegt die Beobachtung zugrunde , dass , wenn die multivariable Funktion ist definiert und differenzierbar in einer Nachbarschaft eines Punktes , dann verringert sich am schnellsten , wenn man aus geht in Richtung des negativen Gradienten der an . Daraus folgt, wenn





für eine kleine genug, dann . Mit anderen Worten, der Term wird abgezogen, weil wir uns gegen den Gradienten zum lokalen Minimum bewegen wollen. Mit dieser Beobachtung im Hinterkopf beginnt man mit einer Schätzung für ein lokales Minimum von und betrachtet die Folge so, dass






Wir haben eine monotone Folge

die Folge konvergiert also hoffentlich gegen das gewünschte lokale Minimum. Beachten Sie, dass sich der Wert der Schrittweite bei jeder Iteration ändern darf. Mit bestimmten Annahmen über die Funktion (z. B. konvex und Lipschitz ) und bestimmten Wahlmöglichkeiten von (z. B. ausgewählt entweder über eine Liniensuche , die die Wolfe-Bedingungen erfüllt , oder die Barzilai-Borwein-Methode wie folgt gezeigt),



![{\displaystyle \gamma_{n}={\frac {\left|\left(\mathbf{x}_{n}-\mathbf{x}_{n-1}\right)^{T}\left [\nabla F(\mathbf{x}_{n})-\nabla F(\mathbf{x}_{n-1})\right]\right|}{\left\|\nabla F(\mathbf {x}_{n})-\nabla F(\mathbf{x}_{n-1})\right\|^{2}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a4bd0be3d2e50d47f18b4aeae8643e00ff7dd2e9)
Konvergenz zu einem lokalen Minimum kann garantiert werden. Wenn die Funktion ist konvex , sind alle lokalen Minima auch globalen Minima, also in diesem Fall Gradientenabfallsaktualisierung zur globalen Lösung konvergieren kann.
Dieser Vorgang ist im nebenstehenden Bild dargestellt. Hier wird angenommen, dass sie auf der Ebene definiert ist und dass ihr Graph eine Schüsselform hat. Die blauen Kurven sind die Höhenlinien , dh die Bereiche, in denen der Wert von konstant ist. Ein roter Pfeil, der von einem Punkt ausgeht, zeigt die Richtung des negativen Gradienten an diesem Punkt an. Beachten Sie, dass der (negative) Gradient an einem Punkt orthogonal zu der durch diesen Punkt verlaufenden Höhenlinie verläuft. Wir sehen , dass Gradienten Abstieg führt uns auf den Boden der Schüssel, die bis zu dem Punkt, wo der Wert der Funktion minimal ist.
Eine Analogie zum Verständnis des Gradientenabstiegs
.jpg)
Die grundlegende Intuition hinter dem Gradientenabstieg kann durch ein hypothetisches Szenario veranschaulicht werden. Eine Person steckt in den Bergen fest und versucht hinunterzukommen (dh versucht, das globale Minimum zu finden). Es herrscht starker Nebel, so dass die Sicht extrem gering ist. Daher ist der Weg den Berg hinunter nicht sichtbar, daher müssen sie lokale Informationen verwenden, um das Minimum zu finden. Sie können die Methode des Gradientenabstiegs verwenden, bei der die Steilheit des Hügels an ihrer aktuellen Position betrachtet und dann in die Richtung mit der steilsten Abfahrt (dh bergab) vorgegangen wird. Wenn sie den Gipfel des Berges (dh das Maximum) finden wollten, würden sie in Richtung des steilsten Aufstiegs (dh bergauf) vorgehen. Mit dieser Methode würden sie schließlich ihren Weg den Berg hinunter finden oder möglicherweise in einem Loch (dh einem lokalen Minimum oder einem Sattelpunkt ) wie einem Bergsee stecken bleiben . Nehmen Sie jedoch auch an, dass die Steilheit des Hügels bei einfacher Beobachtung nicht sofort ersichtlich ist, sondern ein ausgeklügeltes Messinstrument erforderlich ist, das die Person im Moment zufällig besitzt. Es dauert einige Zeit, die Steilheit des Hügels mit dem Instrument zu messen, daher sollten sie den Gebrauch des Instruments minimieren, wenn sie den Berg vor Sonnenuntergang hinunterfahren möchten. Die Schwierigkeit besteht dann darin, die Häufigkeit zu wählen, mit der die Steilheit des Hügels gemessen werden soll, um nicht von der Spur abzuweichen.
In dieser Analogie repräsentiert die Person den Algorithmus, und der Weg, den man den Berg hinunter nimmt, repräsentiert die Abfolge von Parametereinstellungen, die der Algorithmus untersuchen wird. Die Steilheit des Hügels repräsentiert die Steigung der Fehlerfläche an diesem Punkt. Das zur Messung der Steilheit verwendete Instrument ist die Differentiation (die Steigung der Fehlerfläche kann berechnet werden, indem die Ableitung der quadratischen Fehlerfunktion an diesem Punkt gebildet wird). Die Richtung, in der sie sich bewegen, richtet sich nach dem Gradienten der Fehleroberfläche an diesem Punkt. Die Zeit, die sie zurücklegen, bevor eine weitere Messung durchgeführt wird, ist die Schrittgröße.
Beispiele
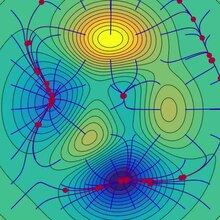
Der Gradientenabstieg hat Probleme mit pathologischen Funktionen wie der hier gezeigten Rosenbrock-Funktion .

Die Rosenbrock-Funktion hat ein schmales geschwungenes Tal, das das Minimum enthält. Die Talsohle ist sehr flach. Aufgrund des gekrümmten flachen Tals geht die Optimierung im Zickzack langsam mit kleinen Schrittweiten zum Minimum hin. Der Whiplash Gradient Descent löst dieses Problem insbesondere.

Die Zickzack-Natur der Methode wird auch unten deutlich, wo die Gradientenabstiegsmethode angewendet wird auf

.png)
.png)
Schrittgröße und Abstiegsrichtung wählen
Da die Verwendung einer zu kleinen Schrittweite die Konvergenz verlangsamen würde und eine zu große zu einer Divergenz führen würde, ist das Auffinden einer guten Einstellung von ein wichtiges praktisches Problem. Philip Wolfe sprach sich auch dafür aus, "kluge Entscheidungen der [Abstiegs-]Richtung" in der Praxis zu verwenden. Während die Verwendung einer Richtung, die von der steilsten Abstiegsrichtung abweicht, kontraintuitiv erscheinen mag, besteht die Idee darin, dass die kleinere Steigung dadurch ausgeglichen werden kann, dass sie über eine viel längere Distanz aufrechterhalten wird.
Um dies mathematisch zu begründen, verwenden wir eine Richtung und Schrittweite und betrachten das allgemeinere Update:


- .

Das Finden guter Einstellungen von und erfordert ein wenig Nachdenken. Zunächst möchten wir, dass die Update-Richtung bergab zeigt. Mathematisch den Winkel zwischen und bezeichnen zu lassen , erfordert dies: Um mehr zu sagen, benötigen wir mehr Informationen über die Zielfunktion, die wir optimieren. Unter der ziemlich schwachen Annahme, die stetig differenzierbar ist, können wir beweisen, dass:



-
( 1 )
![{\displaystyle F(\mathbf{a}_{n+1})\leq F(\mathbf{a}_{n})-\gamma_{n}\|\nabla F(\mathbf{a}_ {n})\|_{2}\|\mathbf {p}_{n}\|_{2}\left[\cos\theta_{n}-\max_{t\in [0,1 ]}{\frac{\|\nabla F(\mathbf{a}_{n}-t\gamma_{n}\mathbf{p}_{n})-\nabla F(\mathbf{a}_ {n})\|_{2}}{\|\nabla F(\mathbf{a}_{n})\|_{2}}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1433794e842e36580db8fa219ae5ca650010d6d6)
Diese Ungleichung impliziert, dass der Betrag, um den wir sicher sein können, dass die Funktion verringert wird, von einem Kompromiss zwischen den beiden Termen in eckigen Klammern abhängt. Der erste Term in eckigen Klammern misst den Winkel zwischen der Abstiegsrichtung und der negativen Steigung. Der zweite Term misst, wie schnell sich der Gradient entlang der Abstiegsrichtung ändert.
Grundsätzlich Ungleichheit ( 1 ) könnte optimiert werden , über und um eine optimale Schrittgröße und die Richtung zu wählen. Das Problem besteht darin, dass die Auswertung des zweiten Termes in eckigen Klammern die Auswertung von erfordert und zusätzliche Gradientenauswertungen im Allgemeinen teuer und unerwünscht sind. Einige Möglichkeiten, dieses Problem zu umgehen, sind:

- Verzichten Sie mit der Einstellung auf die Vorteile einer cleveren Abstiegsrichtung und verwenden Sie die Liniensuche , um eine geeignete Schrittweite zu finden , die beispielsweise die Wolfe-Bedingungen erfüllt .
- Unter der Annahme, dass dies zweimal differenzierbar ist, verwenden Sie dessen Hessian, um zu schätzen. Dann wähle und Optimiere die Ungleichung ( 1 ).
- Angenommen, dies ist Lipschitz , verwenden Sie ihre Lipschitz-Konstante, um dann zu wählen und zu binden , indem Sie die Ungleichung ( 1 ) optimieren .
- Erstellen Sie ein benutzerdefiniertes Modell von für . Wählen Sie dann und durch Optimierung der Ungleichung ( 1 ).
- Unter stärkeren Annahmen über die Funktion wie Konvexität sind möglicherweise fortgeschrittenere Techniken möglich.





![{\displaystyle \max _{t\in [0,1]}{\frac {\|\nabla F(\mathbf {a} _{n}-t\gamma_{n}\mathbf {p} _{ n})-\nabla F(\mathbf{a}_{n})\|_{2}}{\|\nabla F(\mathbf{a}_{n})\|_{2}}} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/982e8508a3147c2ba4e45b7f88fdda4727d13699)
Normalerweise kann die Konvergenz zu einem lokalen Minimum durch Befolgen eines der obigen Rezepte garantiert werden. Wenn die Funktion ist konvex , sind alle lokalen Minima auch globalen Minima, also in diesem Fall Gradientenabfallsaktualisierung zur globalen Lösung konvergieren kann.
Lösung eines linearen Systems

Gradientenabstieg kann verwendet werden, um ein System linearer Gleichungen zu lösen

als quadratisches Minimierungsproblem umformuliert. Wenn die Systemmatrix real ist symmetrisch und positiv definit wird eine Zielfunktion , wie die quadratische Funktion definiert ist , mit Minimierung


so dass

Für eine allgemeine reelle Matrix , linearen kleinsten Quadrate definieren

In traditionellen linearen kleinsten Quadraten für reelle und die euklidische Norm wird verwendet, in diesem Fall


Die Liniensuchminimierung , die bei jeder Iteration die lokal optimale Schrittweite findet, kann für quadratische Funktionen analytisch durchgeführt werden, und explizite Formeln für das lokal optimale sind bekannt.
Zum Beispiel kann für reelle symmetrische und positiv-definite Matrix ein einfacher Algorithmus wie folgt aussehen:

Um eine Multiplikation mit dem Doppelten pro Iteration zu vermeiden , beachten wir, dass impliziert , was den traditionellen Algorithmus ergibt,



Die Methode wird selten zum Lösen linearer Gleichungen verwendet, wobei die konjugierte Gradientenmethode eine der beliebtesten Alternativen ist. Die Anzahl der Gradientenabstieg Iterationen ist auf die spektrale üblicherweise proportional Konditionszahl der Systemmatrix (das Verhältnis der maximalen zu der minimalen Eigenwerte von ) , während die Konvergenz der konjugierten Gradientenmethode typischerweise durch eine Quadratwurzel der Konditionszahl bestimmt wird, das heißt , ist viel schneller. Beide Methoden können von der Vorkonditionierung profitieren , bei der der Gradientenabstieg möglicherweise weniger Annahmen über den Vorkonditionierer erfordert.


Lösung eines nichtlinearen Systems
Gradientenabstieg kann auch verwendet werden, um ein System nichtlinearer Gleichungen zu lösen . Unten ist ein Beispiel, das zeigt, wie der Gradientenabstieg verwendet wird, um nach drei unbekannten Variablen x 1 , x 2 und x 3 aufzulösen . Dieses Beispiel zeigt eine Iteration des Gradientenabstiegs.
Betrachten Sie das nichtlineare Gleichungssystem

Wir führen die zugehörige Funktion ein

wo

Man könnte nun die Zielfunktion definieren
![{\displaystyle F(\mathbf{x})={\frac{1}{2}}G^{\mathrm {T}}(\mathbf{x})G(\mathbf{x})={\frac {1}{2}}\left[\left(3x_{1}-\cos(x_{2}x_{3})-{\frac {3}{2}}\right)^{2}+\ left(4x_{1}^{2}-625x_{2}^{2}+2x_{2}-1\right)^{2}+\left(\exp(-x_{1}x_{2}) +20x_{3}+{\frac {10\pi -3}{3}}\right)^{2}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/31ebfa155b6d0cdef7771ecacf28d5179dd9b111)
die wir versuchen zu minimieren. Als erste Vermutung verwenden wir

Wir wissen das

wobei die Jacobi-Matrix gegeben ist durch


Wir berechnen:

Daher

und




Nun muss ein passender gefunden werden, so dass


Dies kann mit jedem einer Vielzahl von getan wird Linie Suchalgorithmen. Man könnte auch einfach erraten, was gibt


Die Auswertung der Zielfunktion bei diesem Wert ergibt

Die Abnahme vom Wert des nächsten Schrittes von


ist eine beträchtliche Abnahme der Zielfunktion. Weitere Schritte würden seinen Wert weiter reduzieren, bis eine ungefähre Lösung für das System gefunden wurde.
Kommentare
Der Gradientenabstieg funktioniert in Räumen beliebiger Dimensionen, sogar in unendlichdimensionalen. Im letzteren Fall ist der Suchraum typischerweise ein Funktionsraum , und man berechnet die Fréchet-Ableitung des zu minimierenden Funktionals, um die Abstiegsrichtung zu bestimmen.
Dass der Gradientenabstieg in beliebig vielen Dimensionen (mindestens endliche Zahl) funktioniert, kann als Folge der Cauchy-Schwarz-Ungleichung gesehen werden . Dieser Artikel beweist, dass der Betrag des inneren (Punkt-)Produkts zweier Vektoren beliebiger Dimension maximiert ist, wenn sie kollinear sind. Im Fall eines Gradientenabstiegs wäre dies der Fall, wenn der Vektor der unabhängigen Variablenanpassungen proportional zum Gradientenvektor der partiellen Ableitungen ist.
Der Gradientenabstieg kann viele Iterationen erfordern , um ein lokales Minimum mit der erforderlichen Genauigkeit zu berechnen , wenn die Krümmung in verschiedenen Richtungen für die gegebene Funktion sehr unterschiedlich ist. Für solche Funktionen heilt die Vorkonditionierung , die die Geometrie des Raums ändert, um die Funktionsniveausätze wie konzentrische Kreise zu formen , die langsame Konvergenz. Das Konstruieren und Anwenden der Vorkonditionierung kann jedoch rechenintensiv sein.
Der Gradientenabstieg kann mit einer Liniensuche kombiniert werden, um bei jeder Iteration die lokal optimale Schrittweite zu finden. Die Durchführung der Leitungssuche kann zeitaufwendig sein. Umgekehrt kann die Verwendung eines festen kleinen Werts zu einer schlechten Konvergenz führen.
Bessere Alternativen können Verfahren sein, die auf dem Newton-Verfahren und der Inversion des Hessischen unter Verwendung von konjugierten Gradiententechniken basieren. Im Allgemeinen konvergieren solche Verfahren in weniger Iterationen, aber die Kosten jeder Iteration sind höher. Ein Beispiel ist die BFGS Methode , die bei jedem Schritt eine Matrix bei der Berechnung besteht , mit dem der Gradientenvektor multipliziert wird , in eine „besseren“ Richtung zu gehen, mit einer anspruchsvolleren kombinierte Linie Suchalgorithmus, den „besten“ Wert zu finden Für extrem Bei großen Problemen, bei denen die Computerspeicherprobleme dominieren, sollte eine Methode mit begrenztem Speicher wie L-BFGS anstelle von BFGS oder dem steilsten Abstieg verwendet werden.

Gradientenabstieg kann als Anwendung der Eulerschen Methode zur Lösung gewöhnlicher Differentialgleichungen auf einen Gradientenfluss betrachtet werden . Diese Gleichung kann wiederum als optimaler Regler für das Regelsystem mit gegebener Rückkopplungsform hergeleitet werden .




Änderungen
Der Gradientenabstieg kann zu einem lokalen Minimum konvergieren und sich in der Nähe eines Sattelpunktes verlangsamen . Selbst bei uneingeschränkter quadratischer Minimierung entwickelt der Gradientenabstieg im Verlauf der Iterationen ein Zick-Zack-Muster aufeinanderfolgender Iterationen, was zu einer langsamen Konvergenz führt. Es wurden mehrere Modifikationen des Gradientenabstiegs vorgeschlagen, um diese Mängel zu beheben.
Schnelle Gradientenmethoden
Yurii Nesterov hat eine einfache Modifikation vorgeschlagen, die eine schnellere Konvergenz für konvexe Probleme ermöglicht und seitdem weiter verallgemeinert wurde. Für unbeschränkte glatte Probleme wird das Verfahren als schnelles Gradientenverfahren (FGM) oder beschleunigtes Gradientenverfahren (AGM) bezeichnet. Insbesondere wenn die differenzierbare Funktion konvex ist und ist Lipschitz , und es wird angenommen , dass nicht ist stark konvex , dann wird der Fehler in dem Ziel - Wert bei jedem Schritt erzeugt durch das Gradientenabstiegsverfahren wird durch begrenzt . Unter Verwendung der Nesterov-Beschleunigungstechnik verringert sich der Fehler bei . Es ist bekannt, dass die Rate für die Abnahme der Kostenfunktion für Optimierungsverfahren erster Ordnung optimal ist. Dennoch besteht die Möglichkeit, den Algorithmus durch Reduzierung des konstanten Faktors zu verbessern. Die optimierte Gradientenmethode (OGM) reduziert diese Konstante um den Faktor zwei und ist eine optimale Methode erster Ordnung für großskalige Probleme.




Für eingeschränkte oder nicht glatte Probleme wird Nesterovs FGM als schnelles proximales Gradientenverfahren (FPGM) bezeichnet, eine Beschleunigung des proximalen Gradientenverfahrens .
Momentum- oder Heavy-Ball- Methode
Beim Versuch, das Zick-Zack-Muster des Gradientenabstiegs zu durchbrechen, verwendet die Impuls- oder Heavy-Ball-Methode einen Impulsterm in Analogie zu einer schweren Kugel, die auf der Oberfläche von Werten der minimierten Funktion gleitet, oder zu einer Massenbewegung in der Newtonschen Dynamik durch ein viskoses Medium in einem konservativen Kraftfeld. Der Gradientenabstieg mit Impuls merkt sich die Lösungsaktualisierung bei jeder Iteration und bestimmt die nächste Aktualisierung als Linearkombination des Gradienten und der vorherigen Aktualisierung. Für unbeschränkte quadratische Minimierung ist eine theoretische Konvergenzratenschranke des Heavy-Ball-Verfahrens asymptotisch dieselbe wie die des optimalen konjugierten Gradientenverfahrens .
Diese Technik wird im Stochastischen Gradientenabstieg#Momentum und als Erweiterung der Backpropagation- Algorithmen verwendet, die zum Trainieren künstlicher neuronaler Netze verwendet werden .
Erweiterungen
Der Gradientenabstieg kann erweitert werden, um Beschränkungen zu handhaben , indem eine Projektion auf den Satz von Beschränkungen eingeschlossen wird. Dieses Verfahren ist nur möglich, wenn die Projektion auf einem Computer effizient berechenbar ist. Unter geeigneten Annahmen konvergiert diese Methode. Dieses Verfahren ist ein spezieller Fall des Vorwärts-Rückwärts-Algorithmus für monotone Einschlüsse (der konvexe Programmierung und Variationsungleichungen umfasst ).
Siehe auch
- Backtracking-Liniensuche
- Konjugierte Gradientenmethode
- Stochastischer Gradientenabstieg
- Rprop
- Deltaregel
- Wolfe-Bedingungen
- Vorkonditionierung
- Broyden-Fletcher-Goldfarb-Shanno-Algorithmus
- Davidon-Fletcher-Powell-Formel
- Nelder-Mead-Methode
- Gauß-Newton-Algorithmus
- Berg steigen
- Quantenglühen
- Kontinuierliche lokale Suche
Verweise
Weiterlesen
- Boyd, Stephen ; Vandenberghe, Lieven (2004). "Uneingeschränkte Minimierung" (PDF) . Konvexe Optimierung . New York: Cambridge University Press. S. 457–520. ISBN 0-521-83378-7.
- Chong, Edwin KP; ak, Stanislaw H. (2013). "Gradientenmethoden" . Eine Einführung in die Optimierung (vierte Aufl.). Hoboken: Wiley. S. 131–160. ISBN 978-1-118-27901-4.
- Himmelblau, David M. (1972). „Uneingeschränkte Minimierungsverfahren mit Derivaten“. Angewandte nichtlineare Programmierung . New York: McGraw-Hill. S. 63–132. ISBN 0-07-028921-2.
Externe Links
- Verwenden des Gradientenabstiegs in C++, Boost, Ublas für die lineare Regression
- Eine Reihe von Videos der Khan Academy bespricht den Gradientenaufstieg
- Online-Buch, das den Gradientenabstieg im Kontext eines tiefen neuronalen Netzwerks lehrt
- „Gradientenabstieg, wie neuronale Netze lernen“ . 3Blau1Braun . 16. Oktober 2017 – über YouTube .
arxiv.org/2108.1283