
eSpeak - eSpeak
| Originalautor(en) | Jonathan Duddington |
|---|---|
| Entwickler | Reece Dunn |
| Erstveröffentlichung | Februar 2006 |
| Stabile Version |
1,50
/ 2. Dezember 2019
|
| Repository | github |
| Geschrieben in | C |
| Betriebssystem |
Linux Windows macOS FreeBSD |
| Typ | Sprachsynthesizer |
| Lizenz | GPLv3 |
| Webseite | github |
eSpeakNG ist ein kompakter Open-Source- Software- Sprachsynthesizer für Linux , Windows und andere Plattformen. Es verwendet eine Formant-Synthese- Methode, die viele Sprachen in einer kleinen Größe bereitstellt. Ein Großteil der Programmierung für die Sprachunterstützung von eSpeakNG erfolgt mithilfe von Regeldateien mit Feedback von Muttersprachlern.
Aufgrund seiner geringen Größe und vielen Sprachen ist es als Standard-Sprachsynthesizer im NVDA Open Source Screenreader für Windows sowie Android, Ubuntu und anderen Linux-Distributionen enthalten. Sein Vorgänger eSpeak wurde 2016 von Microsoft empfohlen und 2010 von Google Translate für 27 Sprachen verwendet; 17 davon wurden später durch kommerzielle Stimmen ersetzt.
Die Qualität der Sprachstimmen variiert stark. In eSpeakNGs Vorgänger eSpeak basierten die ersten Versionen einiger Sprachen auf Informationen, die auf Wikipedia gefunden wurden . Einige Sprachen haben mehr Arbeit oder Feedback von Muttersprachlern erhalten als andere. Die meisten Menschen, die zur Verbesserung der verschiedenen Sprachen beigetragen haben, sind blinde Benutzer von Text-to-Speech.
Geschichte
1995 veröffentlichte Jonathan Duddington den Speak-Sprachsynthesizer für RISC OS- Computer, die britisches Englisch unterstützen. Am 17. Februar 2006 wurde Speak 1.05 unter der GPLv2- Lizenz veröffentlicht, zunächst für Linux , mit einer Windows SAPI 5- Version, die im Januar 2007 hinzugefügt wurde. Die Entwicklung von Speak wurde bis Version 1.14 fortgesetzt, als es in eSpeak umbenannt wurde.
Die Entwicklung von eSpeak wurde ab 1.16 (es gab keine Version 1.15) mit dem Hinzufügen eines eSpeakEdit-Programms zum Bearbeiten und Erstellen der eSpeak-Sprachdaten fortgesetzt. Diese waren bis eSpeak 1.24 nur als separater Quell- und Binärdownload verfügbar. Die Version 1.24.02 von eSpeak war die erste Version von eSpeak, die mit Subversion versioniert wurde , wobei separate Quell- und Binär-Downloads auf SourceForge zur Verfügung gestellt wurden. Ab eSpeak 1.27 wurde eSpeak aktualisiert, um die GPLv3- Lizenz zu verwenden. Die letzte offizielle eSpeak-Version war 1.48.04 für Windows und Linux, 1.47.06 für RISC OS und 1.45.04 für macOS . Die letzte Entwicklungsversion von eSpeak war 1.48.15 am 16. April 2015.
eSpeak verwendet das Usenet-Schema , um Phoneme mit ASCII-Zeichen darzustellen .
eSpeak NG
Am 25. Juni 2010 startete Reece Dunn einen Fork von eSpeak auf GitHub mit der Version 1.43.46. Dies begann mit dem Bemühen, die Erstellung von eSpeak auf Linux und anderen POSIX- Plattformen zu vereinfachen .
Am 4. Oktober 2015 (6 Monate nach der Veröffentlichung von eSpeak 1.48.15) begann dieser Fork deutlicher vom ursprünglichen eSpeak abzuweichen.
Am 8. Dezember 2015 gab es Diskussionen auf der eSpeak-Mailingliste über die mangelnde Aktivität von Jonathan Duddington in den letzten 8 Monaten seit der letzten eSpeak-Entwicklungsversion. Dies führte zu Diskussionen über die Weiterentwicklung von eSpeak in Jonathans Abwesenheit. Das Ergebnis war die Erstellung des espeak-ng (Next Generation) Fork, der die GitHub-Version von eSpeak als Basis für die zukünftige Entwicklung nutzt.
Am 11. Dezember 2015 wurde der espeak-ng Fork gestartet. Die erste Veröffentlichung von espeak-ng war 1.49.0 am 10. September 2016 und enthielt umfangreiche Code-Bereinigungen, Fehlerbehebungen und Sprachaktualisierungen.
Merkmale
eSpeakNG kann als Befehlszeilenprogramm oder als gemeinsam genutzte Bibliothek verwendet werden.
Es unterstützt die Speech Synthesis Markup Language (SSML).
Sprachstimmen werden durch den ISO 639-1- Code der Sprache identifiziert . Sie können durch "Sprachvarianten" modifiziert werden. Dies sind Textdateien, die Eigenschaften wie den Tonhöhenbereich ändern, Effekte wie Echo, Flüstern und Krächzen hinzufügen oder systematische Anpassungen an Formantfrequenzen vornehmen können, um den Klang der Stimme zu ändern. "af" ist zum Beispiel die Stimme Afrikaans. "af+f2" ist die Afrikaans-Stimme, die mit der "f2"-Stimmenvariante modifiziert wurde, die die Formanten und den Tonumfang ändert, um einen weiblichen Klang zu erzeugen.
eSpeakNG verwendet eine ASCII-Darstellung von Phonemnamen, die lose auf dem Usenet-System basiert .
Phonetische Darstellungen können in die Texteingabe eingeschlossen werden, indem sie in doppelte eckige Klammern eingeschlossen werden. Zum Beispiel: espeak-ng -v en "Hallo [[w3:ld]]" sagt Hallo Welt auf Englisch.
![]()
Synthesemethode
eSpeakNG kann auf verschiedene Weise als Text-zu-Sprache-Übersetzer verwendet werden, je nachdem, welchen Text-zu-Sprache-Übersetzungsschritt der Benutzer verwenden möchte.
1. Schritt – Text-zu-Phonem-Übersetzung
Es gibt viele Sprachen (insbesondere Englisch ), die keine direkten Eins-zu-eins-Regeln zwischen Schreiben und Aussprache haben; Daher muss der erste Schritt bei der Text-zu-Sprache-Erzeugung die Text-zu-Phonem-Übersetzung sein.
- Eingabetext wird in Aussprachephoneme übersetzt (zB Eingabetext xerox wird zur Aussprache in zi@r0ks übersetzt ).
- Aussprachephoneme werden zu Lauten synthetisiert, zB wird zi@r0ks monoton als zi@r0ks geäußert
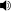
Um Intonation für Sprache hinzuzufügen, sind zB Prosodiedaten (zB Betonung einer Silbe, fallende oder steigende Tonhöhe der Grundfrequenz, Pause, etc.) und andere Informationen notwendig, die es ermöglichen, menschlichere, nicht monotone Sprache zu synthetisieren. Im eSpeakNG-Format wird beispielsweise eine betonte Silbe mit einem Apostroph hinzugefügt: z'i@r0ks, was eine natürlichere Sprache bietet: z'i@r0ks mit Intonation![]()
Zum Vergleich zwei Stichproben mit und ohne Prosodiedaten:
-
[[DIs Iz m0noUntoUn spi:tS]] wird monoton geschrieben
-
[[DIs Iz 'Int@n,eItI2d sp'i:tS]] wird intoniert geschrieben
Wenn eSpeakNG nur zur Generierung von Prosodiedaten verwendet wird, können Prosodiedaten als Eingabe für MBROLA- Diphone-Stimmen verwendet werden.
2. Schritt – Klangsynthese aus Prosodiedaten
Das eSpeakNG bietet zwei verschiedene Arten der Formant- Sprachsynthese mit seinen zwei unterschiedlichen Ansätzen. Mit eigenem eSpeakNG-Synthesizer und einem Klatt-Synthesizer :
- Der eSpeakNG-Synthesizer erzeugt stimmhafte Sprachklänge wie Vokale und sonore Konsonanten durch additive Synthese, die Sinuswellen zum Gesamtklang addiert. Stimmlose Konsonanten, zB /s/, werden durch das Abspielen von aufgenommenen Klängen erzeugt, da sie reich an Obertönen sind, was die additive Synthese weniger effektiv macht. Stimmhafte Konsonanten wie /z/ werden durch Mischen eines synthetisierten stimmhaften Tons mit einem aufgenommenen Sample eines stimmlosen Tons erzeugt.
- Der Klatt-Synthesizer verwendet meistens die gleichen Formant-Daten wie der eSpeakNG-Synthesizer. Aber, es erzeugt auch Geräusche durch subtraktive Synthese von Rauschen mit erzeugten Ausgang, die Harmonischen reich ist, und dann die Anwendung digitale Filter und Kuvertierung zum Ausfiltern notwendigen Frequenzspektrums und Ton - Hüllkurve für bestimmte Konsonanten (s, t, k) oder sonorant ( l, m, n) Laut.
Für die MBROLA- Stimmen wandelt eSpeakNG den Text in Phoneme und zugehörige Tonhöhenkonturen um. Es übergibt dies im PHO-Dateiformat an das MBROLA-Programm und erfasst das in der Ausgabe von MBROLA erstellte Audio. Dieses Audio wird dann von eSpeakNG verarbeitet.
Sprachen
eSpeakNG führt Text-zu-Sprache-Synthese für die folgenden Sprachen durch:
- Abaza
- Ein Chinese
- Fern
- Afrikaans
- albanisch
- Amharisch
- Altgriechisch
- Arabisch 1
- Aragonesisch
- Armenisch ( Ostarmenisch )
- Armenisch ( Westarmenisch )
- Assamesisch
- Aserbaidschanisch
- Baschkirisch
- baskisch
- Grundlegendes Englisch
- Belarussisch
- Bengali
- Bhojpuri
- Bishnupriya Manipuri
- bosnisch
- bulgarisch
- Bretonisch
- birmanisch
- Kantonesisch
- katalanisch
- Cebuano
- Cherokee
- Chichewa
- Chinesisch ( Mandarin )
- Korsisch
- kroatisch
- Tschechisch
- Tschuwaschen
- Kirchenslawisch
- dänisch
- Niederländisch
- Dzongkha
- Englisch ( amerikanisch )
- Englisch ( britisch )
- Englisch ( Karibik )
- Englisch ( Lancastrian )
- Englisch ( empfangene Aussprache )
- Englisch ( Schottisch )
- Englisch ( West Midlands )
- Esperanto
- estnisch
- finnisch
- Philippinisch
- Französisch ( belgisch )
- Französisch ( Frankreich )
- Französisch ( Schweizer )
- Friesisch
- galizisch
- georgisch
- Deutsch
- Griechisch ( modern )
- Grönländisch
- Guarani
- Gujarati
- Hakka-Chinesisch 3
- Haitianisches Kreol
- Hausa
- hawaiisch
- hebräisch
- Hochvalyrian
- Hindi
- Hmong
- ungarisch
- isländisch
- Igbo
- Indonesisch
- Das tue ich
- Interlingua
- Zwischensprache
- irisch
- Italienisch
- Japanisch 4
- Kannada
- Kasachisch
- Khmer
- Klingonisch
- Küche
- Kirundi
- Kinyarwanda
- Konkani
- Koreanisch
- kurdisch
- Kirgisisch
- Quechua
- Ladakh
- Laos
- Latein
- Ladino
- Lettisch
- lettisch
- Lang Belta
- Lingua Franca Nova
- Lepcha
- Limbu
- litauisch
- Lojban
- Luxemburgisch
- mazedonisch
- Maithili
- Madagassisch
- malaiisch
- Malayalam
- maltesisch
- Māori
- Marathi ,
- mongolisch
- Nahuatl ( Klassik )
- Navajo
- Nepalesisch
- Norwegisch ( Bokmål )
- Nord-Sotho
- Nogai
- Odia
- Oromo
- Oktian
- Papiamento
- Palauan
- Paschtu
- persisch
- Persisch ( lateinisches Alphabet ) 2
- Polieren
- Portugiesisch ( Brasilien )
- Portugiesisch ( Portugal )
- Punjabi
- Pyash (eine konstruierte Sprache )
- rumänisch
- Russisch
- Russisch ( Lettland )
- Samoanisch
- Sanskrit
- schottisch Gälisch
- serbisch
- Shan (Tai Yai),
- Sharda
- Sesotho
- Shona
- Sindhi
- Singhalesisch
- slowakisch
- Slowenisch
- somali
- Spanisch ( Spanien )
- Spanisch ( Lateinamerika )
- Swahili
- Schwedisch
- Tadschikisch
- Tamil
- Tataren
- Telugu
- Tibetisch
- Tswana
- Thai
- Turkmenen
- Türkisch
- Tataren
- Uiguren
- ukrainisch
- Urdu
- Usbekisch
- Vietnamesisch ( Zentralvietnamesisch )
- Vietnamesisch ( Nordvietnamesisch )
- Vietnamesisch ( Südvietnamesisch )
- Volapük
- Walisisch
- Wolof
- Xhosa
- Jiddisch
- Yoruba
- Zulu-
- Derzeit wird nur vollständig diakritisiertes Arabisch unterstützt.
- Persisch mit englischen (lateinischen) Zeichen geschrieben .
- Derzeit wird nur Pha̍k-fa-sṳ unterstützt.
- Derzeit werden nur Hiragana und Katakana unterstützt.